* Запазване на изображения
Публикувано на 22 октомври 2015 в раздел Информатика.
Дотук видяхме, че когато запазваме информация на компютър (която не е изначало в основния за компютъра двоичен код), ние извършваме процес на кодиране (преобразуване на информацията в двоичен код посредством алгоритъм), а когато я четем извършваме процес на декодиране (превръщане на двоичния код обратно в удобна за ползване от човек информация). Изображенията не правят изключение. Когато искаме да запазим графики или снимки на компютър, ние ги кодираме в определен графичен файлов формат. Тук ще разгледаме най-популярните графични формати - BMP, GIF, PNG, JPEG и TIFF.
Цветови полета (Color Space)
Общото между всички файлови формати, е че те се изобразяват на компютърния екран чрез т.нар. "пиксели". Всеки пиксел е светеща в определен цвят точка от дисплея. Във най-често използвания при компютърните дисплеи формат RGB (Red, Green, Blue). Обяснено по най-прост начин - пикселът всъщност се състои от три по-малки светещи в различен цвят и интензитет точки. Смесването на тези светлини дава конкретен цвят на екрана. Вижте статията ми за CRT, LCD, LED и OLED за повече информация.
В RGB модела за всеки пиксел се записват три цели числа, които стоят в интервала [0, 255]. Числото 0 представлява пълно отсъствие на цвета, а 255 пълно наличие. Смесването на трите цвята дава и цвета на съответния пиксел. Понеже всяко от трите числа може да се запази в 1 байт, този стандарт често се нарича RGB24 (24 битов RGB) или също така RGB888. Той дава 16777216 възможни цвята. Съществува и стандарт RGB32, при който се добавя още 1 байт, в който се записва т.нар. "алфа канал" (alpha channel). Често се среща и като RGBA. Алфа канала се използва при добавяне на процент на "прозрачност" на пикселите в картинките, а не за добавяне на допълнителни цветове. С него е възможно например в дадена картинка да бъде направен полупрозрачен само определен цвят, а не всичко по картинката. Много удобно представяне на RGB цветовете е като точки в следния куб:
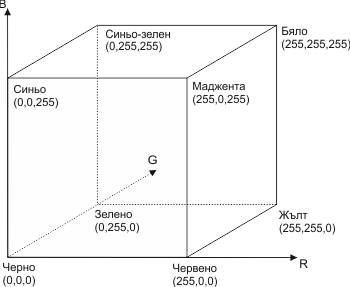
Други възможни стандарти са например 1-битов (0-черно и 1-бял) и 8-битов (обикновено добавящ нюанси на сивото - 0 е черно, а 255 бяло - при черно бели снимки) цвят. При едни от първите компютърни видео карти е имало и стандарт с поддържане на точно 16 основни цвята (4 бита).
Има и 16 битов цвят - 5 бита на цвят и 1 бит за алфа-канал. Той включва 65536 цвята - първоначално за човек изглеждат много, но реално се оказва лесно да се видят разликите с 24 битовия, защото преливанията не са достатъчно плавни. Понякога алфа канала не се използва (неговия бит остава неизползваем. Този формат се нарича RGB555 (по 5 бита на цвят). Негова подобрена модификация е RGB565, което означава, че червения и синия канал използват 5 бита, а зеления взима неизползвания бит и заема 6 бита. Това се прави, защото човешкото око е по-чувствително към зеления цвят.
Възможно е да се използва 8-битов цвят за изобразяване на 256 различни цвята. Това е т.нар. "8-битов индексиран цвят" (с палитра). При него във всеки пиксел се записва число-индекс от 0 до 255. Допълнително към изображението се добавя т.нар. "цветова таблица" - в нея на всеки индекс се съпоставят три байта за R, G и B каналите. Така в крайна сметка ние имаме възможност да оцветим всеки пиксел с един от тези 256 цвята. Друга разновидност е 4-битовия индексиран цвят - при него функцията е същата, но цветовете са само 16. Всъщност по тази схема са възможни всякакви таблици - например 2, 4, 8, 64 или 128 цвята... Поради спецификата на двоичната бройна система е ефективно да са степени на двойката - така използваме числото от индекса максимално ефективно.
Така наречения "дълбок цвят" (deep color) са полета от по 30, 36 или 48-бита. Най-често се среща 30-битовия вариант (често изписван като RGB101010) - при него се пазят по 10 бита за цвят от RGB модела. В този стандарт например кодът на черния цвят е числото 95, а на белия 685. Числата от 685 до 1023 в канала се използват например за реализиране на "по-бяло от бялото" - когато трябва да се представи ефект на ярка експлозия, силно отражение на светлина и т.н. Почти всички съвременни видеокарти поддържат 30-битов цвят. Най-честата му употреба е при high-definition видео - поддържа се от стандарта HDMI 1.3 и по-висок, както и от DisplayPort входовете на съвременните телевизори. Това, че стандарта ги поддържа обаче не означава, че телевизора може да ги възпроизведе - все още масовата техника на пазара продължава да използва 24 битови цветове. Друго поле за употреба е при професионалната обработка на дигитални снимки. По-високите стандарти като 36 и 48-битови пиксели се използват рядко в практиката. Максималният реализиран досега е 64-битов пиксел - 48 битов цвят с 16-битов алфа канал.
RGB е подходящ за дисплеи. Принтерите най-често използват друг формат - CMYK (Cyan, Magenta, Yellow, blacK). Там обикновено се пазят по 8 бита на цвят, или общо 32 бита на пиксел. Това е повече от стандартния RGB модел, тоест при конвертиране от RGB към CMYK може да се очаква, че поне при преноса няма да има загуба на информация. Въпреки това сравнението между двавата модела е много трудно, защото техниката на изобразяване е съвсем различна. При RGB имаме почти плътно сливане на пикселите по екрана, докато при отпечатването с CMYK се използва т.нар. шум (виж dithering по-долу) и halftoning ефекти, които целят да създават оптични илюции с цел пестене на мастило. Затова много често отпечатаното на хартия изглежда доста по-различно от изобразеното на екран, дори той да е отлично калибриран. За по-елементаризирано представяне, можете да приемете следното - CMYK е нещо подобно на рисуването на водни боички върху хартия. Понеже хартията е с бял цвят, вие "отнемате" от бялото - в зависимост какво отнемате се получава един или друг конкретен цвят.
Друго цветово поле е YCbCr. Идеята за него се основава на факта, че човешкото око е по-чувствително към яркостта, отколкото към наситеността на цветовете. Поради тази причина в този формат изображението се разделя на два основни компонента: компонент за яркост и компонент за наситеност, като за яркостта се отделят повече битове. Y е яркостта, а Cb и Cr съдържат цветовата информация. Както ще видим по-късно това спомага за намаляване на обема на информация при прилагане на компресия.
Превръщането на RGB поле в YCbCr може да се получи по различни формули. Често се използва обаче следната:
Y = 0.299*R + 0.587*G + 0.114*B Cb = 128 – 0.168736*R – 0.331264*G + 0.5*B Cr = 128 + 0.5*R – 0.418688*G – 0.081312*B
Обратното превръщане се получава по следния начин:
R = Y + 1.402*(Cr – 128) G = Y – 0.34414*(Cb – 128) – 0.71414*(Cr – 128) B = Y + 1.772*(Cb – 128)
Може да се използват и по-прости формули като например Y = (2*R+3*G+B)/6, но при тях ще има повече загуба на информация от превръщането.
Резолюция
Засега виждате, че цифровите изображения са дискретни (съставени от множество точки-пиксели). Да, но самите пиксели нямат фиксирана големина. На едни монитори пикселите може да са по-голями, отколкото на други. Едно погрешно разбиране за понятието "резолюция" на цифрово изображение е същото като това, което се използва при резолюцията на мониторите - брой пиксели по дъжина и брой пиксели по височина. Това е недостатъчно количество информация за отпечатване на изображението - ние не знаем какви са му реалните размери в милиметри например. Затова към понятието резолюция се включва още една характеристика и тя е "пиксели на инч" (Pixels Per Inch - PPI). Виждате, че по този начин резолюцията дефинира големината (размерите) на пиксела. Това е доста важно при отпечатване на изображение - там пикселите се печатат като мастилни точки на листа хартия (Dots Per Inch - DPI) и обикновено се търси съответствие между PPI и DPI (т.е. всеки пиксел се представя като точка).
Много често в цифровата фотогария ще срещнете понятието "мегапиксел" - милион пиксела. Когато кажем, че даден мобилен телефон има камера, която снима с "5 мегапиксела", това ще означава, че той може да заснема снимки, при които ако умножим броя пиксели по хоризонтала с броя пиксели по вертикала, ще се получи число около 5 милиона (пиксела). Например това може да е резолюция 2560x1920. Забележете, че е това не е единствената комбинация, която може да даде приблизително 5 мегапиксела - такава може да е например и 2984x1680. Броя на пиксели по хоризонтала разделен на броя на пиксели по вертикала дават т.нар. "aspect ratio". В първия пример имаме 4:3, а във втория 16:9.
Стандартните принтери отпечатват изображения с резолюция от 300 до 600 DPI и печатат върху листа с размер A4 (у нас) или Letter (САЩ). Много често с рекламна цел се говори за принтери с огромни DPI, но реална полза от такива резолюции няма (разликите не са видими върху отпечатаните изображения). HD телевизорите например са с резолюция от 1920x1080 (16:9), но тяхното PPI зависи от диагонала на екрана - при 40 инчов телевизор PPI ще е по-голямо спрямо това на 50 инчов телевизор.
При обратния процес - на сканиране на изображения - вие имате възможността да "дигитализирате" физическа рисунка. Тогава има голяма разлика в това дали ще сканирате със 100, 200, 300, 600, 1200 или дори повече DPI. С колкото повече DPI се сканира изображението, толкова по-дребни детайли ще бъдат хванати. За сметка на това файлът с изображението ще заема много по-голям обем информация.
Компресиране със загуба (lossy) и без загуба на качество (lossless)
Много често ще срещате термина "компресиране" на информация. Затова ще дадем следните дефиниции:
(Деф) Некомпресирани са тези данни, които са запазени 1:1 според пряката си кодираща таблица
(Деф) Компресирането е допълнителна обработка на вече кодирана информация, при която се намалява обема на запазените данни
(Деф) Декомпресирането е алгоритъм за превръщане на компресирани в некомпресирани данни
(Деф) Компресиране без загуба се получава тогава, когато при процес на декомпресиране можем да превърнем запазените данни обратно в оригиналния им вид
(Деф) Компресиране със загуба на качество се получава тогава, когато не е възможно запазените данни да бъдат превърнати обратно в оригиналния им вид, а само към тяхно приближение
Нека дадем няколко прости примера за компресиране на информация, като за удобство ще ги илюстрираме с текст, но единицата информация "буква" спокойно би могла да бъде заменена с "пиксел". Представете си, че имате текст "aaaaaaaaaaab". Веднага можете да забележите, че буквата "a" се повтаря 11 пъти. Не можем ли да я запазим само веднъж и да добавим просто едно число за това колко пъти се повтаря? Т.е. например да запишем текста като "11a1b". Със сигурност ще ни трябва някакъв специален разделител, с който да можем да отличаваме числото 11 от текст "11", т.е. компресиращия ни алгоритъм няма да е чак толкова прост, но в случая е по-важна идеята, а именно - вместо да запазваме всички повтарящи се букви, ние пазим само число за броя на повторенията им и по този начин пестим място. Такъв алгоритъм би бил без загуба на информация, защото можем да прочетем оригиналния текст без проблеми. Такъв алгоритъм за компресиране се нарича "компресиране по дължина" (Run Length Encoding - RLE). Той е един от най-простите, но и не много ефективни алгоритми за компресиране.
Ако в RLE няма достатъчно повтарящи се поредици, може да се получи обратния ефект. Например "abcd" би се компресирало като "1a1b1c1d", което е по-лошо от оригинала - вместо намаляване на обема сме получили увеличение. Едно подобрение на RLE e да не пазим число за повторение на единична буква, например "aaaabcccd" би се компресирало като "4ab3cd", а "abcd" просто в "abcd". Тоест в най-лошия случай бихме имали отношение 1:1 между дължината на кодираните и компресираните данни. Още по-добър вариант на RLE е този, в който се следи не за поредици от единични символи (при картинките пиксели), а за групи от такива. Например "abcabcadadadadefg" би се компресирало като "2(abc)4(ad)efg".
Специално при графичните изображения има един частен случай на RLE, който може да се окаже много ефективен при компресиране на изображения с преливащи цветове. Например нека разгледаме следната картинка - в нея имаме преливане по хоризонтала от цвят (200,30,30) към цвят (0,0,0):

Ясно е, че всеки пиксел от дясно е съвсем малко "по-блед" от съседа си вляво, вероятно не съвсем равномерно, но тенденцията е ясна. Нека за по-елементарно разгледаме поредицата като числа, например 1,2,3,5,6,8,9,10,12,13,14,16,... Като допълнение на RLE алгоритъма можем първо да конвертираме тази поредица като пазим първото число и след него разликите между всяка следваща двойка, т.е. първото ще е 1, второто ще е 2-1=1, третото ще е 3-2=1, четвъртото ще е 5-3=2, и т.н. Получава се кодираната поредица 1,1,1,2,1,1,1,2,1,1,1,2,... Това вече може много лесно да бъде записано в RLE алгоритъма като "(n)1112" и да се постигне изключително високо ниво на компресия.
Друг често използван алгоритъм за компресия на изображения е LZW. При него се използват т.нар. "речници" (dictionary). Нека разгледаме компресия на символи - например 8 битови ASCII. LZW започва с речник от 256 символа, на които се съпоставят числа, т.е. съответната ASCII кодировка, която използваме. Започвайки да чете файла, алгоритъма записва всяка нова срещната поредица от символи (първоначално срички, по-нататък и по-дълги поредици от букви) като допълнителен запис с нов номер в речника. Така речника ще продължи да расте до определен предварително максимален размер - например за текст стандартно 4096 записа. Текстът от тук нататък се кодира като записваме само числата от речника. При дълъг текст се постига висока ефективност на компресия. Сега си представете, че вместо символи запазваме тройки байтове - цветове от RGB модела и ще видите как тази компресия може да бъде използвана при изображения.
Как би изглеждало компресиране със загуба на информация? Най-простият пример е с намаляване на резолюцията на дадена снимка. Представете си, че имате снимка с резолюция 3648 пиксела по дължина и 2736 пиксела по височина (приблизително 10 мегапиксела в отношение 4:3). Прилагате следния алгоритъм - по колони пропускате 3 пиксела по хоризонтала и записвате само 4-тия, както и пропускате 3 реда по вертикала и записвате само 4-тия. Това би смалило снимката ви до размер 912 на 684 - ще пазите едва 625632 (0,6 мегапиксела) в същото отношение. След като вече сте запазили информацията веднъж по този начин, бихте ли могли да разширите снимката обратно до оригиналния ѝ размер? Въпросът е реторичен, защото това няма как да бъде възможно - пропуснатите пиксели няма как да бъдат възстановени, защото информацията за тях не е била записана. Това естествено е най-простия пример. Съществуват алгоритми за компресиране използващи интерполация (приближение) на оригиналните данни, така че да дават приблизителни до оригинала резултати, но в много по-малък размер.
Друг тривиален пример за компресия е редукция на цветовете - да отделим по-малко битове за цветовете на пикселите, отколкото е бил оригинала. Например можем да редуцираме 24 битовия RGB цвят до 8 битов индексиран цвят и да "замажем" грубите разлики при преливането на цветовете чрез добавяне на шум (dithering). Пример за това ще видим по-долу.
Компресирането при YCbCr цветово поле се прави чрез т.нар. "subsampling" и е със загуба на информация. Идеята е в някои пиксели да се пази цялата информация, а в други цветовата информация да се пропуска (по този начин се получава нещо подобно на добавянето на шум - виж по-долу):
- 4:4:4 - няма загуба на информация, а във всеки пиксел се пази всичко налично;
- 4:2:2 - във всяка нечетна колона от пиксели се пази цялата информация, а във всяка четна се пази само Y канала;
- 4:1:1 - на всеки четири колони от пиксели се пази пълната информация само в първата колона, а в останалите три колони се пази само Y канала.
Можете да ги запомните така - 4:4:4 е без загуба на информация, 4:2:2 е с 1/2 загуба в хоризонтално направление, 4:1:1 е с 1/4 загуба в хоризонтално направление. Има и още варианти, като например 4:2:0, което е 1/2 загуба както в хоризонтално, така и във вертикално направление (т.е. освен по колони се пропуска информация и по редове). Възможен вариант е и 4:1:0. Извън описаните 3 обаче другите се използват много рядко. Възстановяването на информацията след извършване на различен от 4:4:4 subsampling става чрез интерполация - цветовете от пикселите, в които не пазим цветова информация, се приемат като усреднени стойности на своите съседи.
Накрая ще споменем накратко и един много често използван, но сравнително с останалите доста сложен алгоритъм за компресия - този на Хъфман. При него се брои честотата на срещане на всеки един пиксел, след което им се дава тегло (винаги степен на 2 - по-често срещаните са с по-голямо тегло). С получените тегла се строи бинарно дърво, в което най-често срещаните пиксели ще се подредят близо до корена, а най-рядко срещаните към листата. Бинарно означава, че по-големите (числово) пиксели се слагат от дясно на корена, а по-малките от ляво. Понеже теглата са били степени на двойката, дървото е бинарно, т.е. придвижването по него, за да се намери даден елемент, може да се разгледа като поредица от 0 и 1 (например 001011 би означавало "два пъти наляво, веднъж надясно, веднъж на ляво и два пъти на дясно"). Тоест по този начин заменяме структурата от данни "пиксел" с бинарно число. Понеже по-често срещаните ще са с по-късо бинарно число, те ще се кодират като значително къси поредици от битовe. Самите дървета се запазват като неразделна част от данните (без тях не можем да възстановим оригинала).
Шум (dithering)
Когато искаме да прехвърлим едно изображение с много цветове във формат с по-малко цветове (например отпечатваме пълноцветна фотография на черно-бял принтер) естествено имаме загуба на информация. В по-крайните случаи това може да доведе до неразбираемо изображение. Например ако превърнем преливащия червен цвят от картинката по-горе в еднобитово (черно-бяло) изображение, бихме получили нещо подобно на това:

Наистина отляво е по-наситения черен, а в дясно белия цвят, т.е. "преливане" има, но стъпката е толкова груба, че вече между двете картинки не се вижда никаква връзка. Един начин да замаскираме този проблем е да добавим "шум" - dithering. Има различни алгоритми за добавяне на шум. Например Ordered:
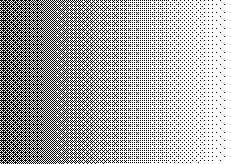
или Jarvis:

Виждате, че изображението наподобява повече оригинала, въпреки огромната загуба на информация (освен цветовите канали, сме загубили и 7 бита информация за преливането от черно в бяло).
Ето пример за снимка с 4-битов индексиран цвят с dithering:

и същата снимка без dithering:

Можете да видите как шума помага значително в региона по лицето и по якето на детето.
RAW формат
Във фотографията много често се използва т.нар. необработен (RAW) формат. Въпреки, че при различните производители има известни разлики, в общи линии RAW формата е некомпресирано изображение. Обикновено са в sRGB формат (стандартизиран за компютърни монитори вариант за изобразяване на RGB), т.е. записват по 3 байта за всеки пиксел, но това не е задължително - има и други формати, като например Adobe RGB, който грубо отнема около 40% повече дисково пространство (и добавя повече цветове. Ако H е броя пиксели по хоризонтала, W е броя пиксели по вертикала, B е броя битове на пиксел, то можете да изчислите броя мебибайти (Fsize, които отнема една RAW снимка по формулата:
Fsize = H*W*B/(8*1024*1024)
Например 10 мегапикселовата снимка 3648x2736 с 3 байта на пиксел би отнела 3648*2736*24/(8*1024*1024) = 28,56MB. Това както сами виждате е значителна големина на файл. Поради тази причина за запазване на снимки най-често се използва компресия - обикновено JPEG.
BitMaP (BMP) файлове
BMP версия 3 форматът за запазване на изображения се появява през 1991 г. с излизането на Windows 3.0 (има и предишни версии, които не са толкова популярни). Той е без загуба на качество и много прилича на вече описания формат RAW с тази разлика, че добавя заглавна част на изображението (т.нар. header), който улеснява софтуерните продукти при процеса на декодиране. С времето при по-нови версии на Microsoft Windows стандарта търпи известни редакции, които са с обратна съвместимост. Тук ще дадем само най-общо описание, без прекалено специфични детайли.
BMP поддържа RLE, но в практиката компресирането се използва много рядко - най-често картинки записани в BMP са некомпресирани. В общи линии повечето редактори на изображения записват информацията във формата от версия 3. Числата се записват в Little Endian. Всяка снимка в BMP формат се състои от четири основни компонента:
- Заглавна част на файла (file header): метаданни, които описват файла.
- В първите 2 байта се записват буквите "BM";
- В следващите 4 байта се записва число - големината на файла в байтове;
- Следващите 4 байта са нулеви - те са резервирани за да се опише софтуера, с който е записан файла, но реално не се използват при декомпресия;
- Накрая има отместване (offset) - това е 4 байтово число, което указва къде във файла започва самата картинка (използва се, за да се прескочат другите описателни части от следващите точки, както и да се определи тяхната големина).
- Заглавна част на картинката (image header):
- 4 байта указващи големината на image header в байтове (в различните стандарти на BMP може броя пиксели по широчина и височина да се записват в 2, вместо в 4 байта, както да има и други разлики);
- 4 байта за ширина на картинката - брой пиксели;
- 4 байта за височина на картинката - брой пиксели;
- 2 байта за брой полета (planes) - засега в стандарта е позволено само 1, затова се записва числото 1;
- 2 байта за число указващо броя битове за пиксели - 1, 2, 4, 8, 16, 24 или 32;
- 4 байта указващи типа на компресията - 0 ще е некомпресиран, 1 RLE за 8 битови картинки, 2 за RLE при 4 битови картинки и 3 за "bitfields" - използва се само при 16 и 32 битови картинки и с него се дефинира, че има алфаканал, т.е. се използва RGBA. Във версии на BMP от Windows 95 нагоре е възможно да има 4 за bi-jpeg и 5 за bi-png - това всъщност указва, че картинката ще е в съвсем друг формат (JPG или PNG, за които ще говорим по-късно). Стойности от 6, 7 и 8 указват, че BMP картинката е записана с CMYK цветово поле, като съответно е некомпресирано, 8-битово или 4-битово;
- 4 байта за големина на картинката в байтове - обикновено се държи със стойност 0 при некомпресирани картинки. Има значение само при компресирани (нещо като checksum);
- 4 байта за "пиксели на метър" по ширина;
- 4 байта за "пиксели на метър" по височина;
- 4 байта за това колко индекса от цветовата таблица (по-долу) се използват ефективно;
- 4 байта за число указващо "важните цветове" - има отношение при изобразяване на снимката на устройство, което поддържа по-малко цветове, отколкото са записани.
- Цветова таблица (color table) - използва се само при картинки с 8 или по-малко бита на пиксел. В цветовата таблица се записват индекси и цветове на палитрата за текущата снимка;
- Пиксели записани от ляво на дясно и отгоре надолу
- 1-битови пиксели - записват се в поредица от байтове, естествено по 8 в байт. Ако в последния байт в редовете има по-малко от 8 пиксела, оставащите свободни бита се държат 0;
- 4-битови пиксели - записват се в поредица от байтове, по 2 пиксела в байт. Ако в последния байт в редовете има само един пиксел, последните 4 бита са нулеви;
- 8-битови пиксели - всеки байт определя точно един пиксел;
- 16-битови пиксели - всеки пиксел се записва в 2 байта. Възможно е да се използва RGB555 или RGB565;
- 24-битови пиксели - всеки пиксел се записва в 3 байта. Това е стандартния RGB24 формат;
- 32-битови пиксели - всеки пиксел се записва в 4 байта. Най-често се използва за 30 битов цвят, т.е. RGB101010. Понякога в 32-битовите BMP се запазва и RGB888 (стандартния RGB24) пиксел. Това е разхищение на информация от една страна, но води до известно ускорение при обработката на информация (заради процесорите, които ще работят с парчета по точно 32 бита) от друга.
Виждате, че BMP форматът е гъвкав и е без загуба на информация. Наличието на header и поддръжката на много цветови полета го прави по-адекватен избор спрямо RAW. Недостатък спрямо конкурентните формати е слабата (в повечето случаи никаква) компресия, което води до много големи файлове.
CompuServe GIF
Graphics Interchange Format (GIF) e формат за компресия на картинки без загуба на качество. Използва LZW компресията, която описахме по-горе. Поддържа от 1 до 8 битови индексирани цветове, т.е. поддържа максимум 256 цвята. Подходящ е за графики като например знаци и лога, които са без преливания на цветове и с ясни контурни линии. Разширението на формата GIF89a позволява и запазване на анимации от поредни картинки записани в един файл. Възможно е един от цветовете в палитрата да се дефинира като прозрачен - често се използва за прозрачност на фона на картинката. Всички числа се записват в little endian формат. Важно качество за анимираните GIF файлове е, че се пазят само разликите в различните кадри от анимацията, което позволява значително добра компресия на кадрите.
Концептуално GIF дефинира поле наречено "логически екран". На него може да бъде разположена една или повече картинки (когато са много се използва за анимация). Подобно на BMP започва със заглавна част (header), който е следния (байтовете в изредения списък са подредени от начало към края):
- 5 байта: съдържа ASCII букви с името на формата - "GIF89a";
- 2 байта: ширината на логическия екран;
- 2 байта: височината на логическия егран
- 1 байт: определител на глобална цветова таблица (global color table - GCT).
- 1 бит - ако е 0, няма такава таблица (и останалите битове в този байт също губят смисъл). Ако е 1, ще има GCT;
- 3 бита - число ColorBitDepth указващо броя битове за цвят в цветовата таблица. Например 000 ще означава, че запазваме 2-битови цветове, а 111 ще означава 8-битови цветове;
- 1 бит - сортиращ флаг. Ако е 1, това означава, че цветовете в GCT ще са сортирани по значимост (първите цветове в таблицата се считат за по-често срещани, т.е. по-важни, от тези в края на таблицата). Ако е 0, няма такова сортиране. Този флаг няма особено значение при съвременната техника - навремето се е считало, че подпомага декодера на файла, като може да го прави по-бърз (кеширайки важните стойности);
- 3 бита - определят големината (броя на байтовете) на GCT - ще я наречем GCTSize
- 1 байт: индекс на фонов цвят - има отношение към прозрачност;
- 1 байт: отношение ширина/височина на пиксела (pixel aspect ratio) - стойност, която няма особен смисъл днешно време и почти винаги се пропуска. Оригиналната идея е била да се определи отношението между страните на пиксела разгледан като правоъгълник - имало е някакъв смисъл при превръщане на сигнал от аналогова телевизия в цифров. Ако в този байт има ненулева стойност N, отношението се пресмята по формулата (N+15)/64;
След този header следва описанието на GCT (освен ако не е изключено, но това е много рядък случай, при който ще се използват 256 основни цвята по подразбиране). Размерът на GCT би бил следния: 3*2^(ColorBitDepth+1) - умножаваме по 3, защото за всеки запис се пазят по три цвята. Съдържанието на GCT е наредена поредица от тройки RGB цветове, толкова на брой, колкото цветове сме дефинирали преди това.
След GCT следва блок за разширение на графичния контрол (graphics control extension). Използва се само при дефиниране на прозрачност на фона или при анимирани GIF файлове (описание на всеки кадър сам за себе си). Неговата структура (ако го има) e следната:
- 1 байт: въвеждащ елемент. Винаги е със стойност 21 hex (десетично 33);
- 1 байт: контролен знак. Винаги е със стойност F9 (десетично 241);
- 1 байт: големина на блока в байтове;
- 1 байт: описателно поле (packet field):
- 3 бита - резервирани за бъдещо ползване, засега се държат празни;
- 3 бита - разпореждащ метод (disposal method). Стойността тук е важна само ако имате анимация. В общи линии тук се отговаря на въпроса "какво да правим с предишния кадър?". Възможните стойности са 0 do not dispose - пиксели, които не са покрити от новия кадър, ще останат така, както са си, 1 dispose to background - фоновия цвят ще прозира през прозрачния цвят на новия кадър (вместо да прозира предишния кадър), 2 restore to previous - след края на кадъра ще върне кадъра преди него, 3 нищо - не е определен, т.е. кадрите се натрупват един върху друг. Няма да навлизаме в подробности, но тук са възможни 8 вида ефекта в анимацията в зависимост от това дали всички кадри заедно имат/нямат прозрачен фон или са смесени (някои кадри имат, други нямат прозрачност);
- 1 бит - флаг за потребителска интеракция (user input flag). Указва дали анимацията ще започне автоматично (0) или потребителя ще трябва да цъкне с мишката;
- 1 бит - флаг за прозрачен цвят.
- 2 байта: време за изчакване между кадрите (важи за анимациите - преминаване от един кадър в друг). Ако няма анимация се държи на 00;
- 2 байта: индекс на прозрачния цвят (от GCT таблицата);
- 2 байта: край на блока (винаги със стойност 00).
От тук нататък следва поредица от една или повече картинки, които ще се разположат в логическия екран. Те от своя страна се състоят от два компонента. Първи е описанието на самата картинка (image descriptor), който е точно 10 байта:
- 1 байт: разделител на картинките (винаги hex стойност 2C или десетично 44);
- 2 байта: координати по х на северозападния ъгъл на картинката в логическия екран. Обикновено го държим 00, т.е. ляво;
- 2 байта: координати по y на северозападния ъгъл. Обикновено го държим 00, т.е. горе;
- 2 байта: големина в пиксели за ширина на картинката - обикновено съвпада с ширината на логическия екран;
- 2 байта: големина в пиксели за височина на картинката - обикновено съвпада с височината на логическия екран;
- 1 байт: описателно поле (packet field):
- 1 бит - локална цветова таблица - това е възможност всеки кадър да има своя собствена таблица. Не се използва често;
- 1 бит - interlace - начин за рендериране на картинките;
- 1 бит - сортиращ флаг - за значимост на цветовете на локалната цветова таблица по подобие на глобалната;
- 1 бит - неизползван;
- 3 бита - големина на локалната цветова таблица.
Следва (ако се използва) локална цветова таблица за картинката - има същия формат като глобалната, затова няма да я описваме. Накрая следва и самата картинка, която е компресирана с LZW алгоритъм. Няма да описваме подробно структурата, защото самия алгоритъм е достатъчно дълъг за описание. За по-любознателните вижте тук: https://www.cs.cmu.edu/~cil/lzw.and.gif.txt
{kind=link}
Ако GIF файла е анимиран, има още Image Descriptor и данни на картинките. GIF файлът завършва с 3B (десетично 59), което е знак за край на файла.
В GIF89a има допълнително Plain Text, Application и Comments разширения. Plain Text не се използва никога (софтуерните продукти не го поддържат) - било е предвидено за реализиране на нещо като субтитри върху картинките. Application разширението е поредица от битове, в които може да се дават конкретни настройки за различни приложения. Използва се много рядко и практическото му приложение обикновено се свежда до конкретна комбинация от 19 бита (т.нар. Netscape 2.0 extension), които позволяват на анимиран GIF да повтаря анимацията "до безкрайност" (всъщност 65535 пъти):
21 FF 0B 4E 45 54 53 43 41 50 45 32 2E 30 03 01 00 00 00
N E T S C A P E 2 . 0 ∞ ∞ ∞
В Comments раздела може да се добавя обикновен ASCII код. Започва с 21 FE, след което два байта за дължина на текста последвани от самия текст. В края е затварянето на блока - 00.
Portable Network Graphics (PNG)
Форматът PNG е създаден в средата на 90-те като алтернатива на лимитирания откъм брой цветове GIF. Въпреки, че отначало се налага сравнително бавно, в днешно време PNG е най-често използвания формат за графики в интернет. PNG обаче не поддържа анимации (такива има в друг надграждащ PNG формат MNG, който обаче почти не се използва), поради което не може да се смята за пълна алтернатива на GIF. Освен това GIF дава по-добра компресия при малки по размер картинки. За сметка на това PNG винаги дава по-малки по размер файлове при големи картинки и освен това поддържа пълноцветни картинки и алфа канал, с който фона да стане полупрозрачен - това са значителни подобрения спрямо GIF.
PNG е формат за запазване на изображения без загуба на информация. Поддържа 24-битов RGB, 32-битов RGBA, 8-битови картинки с нюанси на сивото и индексирани цветове. Основната структура на PNG включва заглавна част от 8 байта (header) и поредица от "парчета" (chunks) от графична информация. Всички числа се записват в Big Endian формат.
Заглавната част e винаги една и съща за всеки файл. В шеснадесетичен формат тя е:
89 50 4E 47 0D 0A 1A 0A P N G CR LF ^Z LF
Първият байт е контролен и се използва най-вече за това да не бъдат погрешно интерпретирани текстови файлове (започващи с буквите PNG...) като графични. Буквите P, N и G указват формата на файла. CR e край на ред за Макинтош, а LF за Unix - комбинацията от двете в този ред пък е стандарт за край на ред в Windows. Седмият байт (^Z или CTRL-Z) е символ за край на файл - по този начин се цели ако някой отвори PNG файл в обикновен текстови редактор да вижда само буквите PNG, без останалата информация.
От там насетне, както вече казахме, следва поредица от "chunks" - парчета от информация за изображението. Тяхната структура е такава, че да могат да бъдат обработвани бързо от софтуерни продукти и до известна степен да могат да се разгледат като самостоятелни части от изображението или метаданни за него. Структурата на всяко парче е следната:
- 4 байта указващи дължина (брой байтове) на даните (т.е. само на третата точка от това изброяване);
- 4 байта указващи типа на парчето;
- До максимум 2GB данни;
- 4 байта CRC (използва се за проверка на интегритета на данните).
Първото, което трябва да разгледаме е типа на парчето. Той се указва чрез комбинация от четири ASCII букви от английската азбука. На макро ниво те могат да бъдат интерпретирани по следния начин:
- Първата буква указва дали парчето е "критично" (буквата ще е главна) или "спомагателно" (буквата е малка). Критичните парчета са такива, без които изображението не би могло да бъде възпроизведено. Спомагателните биха могли да бъдат пропуснати, въпреки че е нежелателно;
- Втората буква указва дали парчето е "публично" (главна) или "частно" (малка). Публичните са строго регламентирани в стандарта. Ако някоя фирма желае да вгради своя собствена информация вътре в PNG файл, която е извън официалната спецификация, тя може да го направи чрез своя малка буква;
- Третата буква на този етап е само главна - малките букви за трети символ са резервирани за бъдещо ползване;
- Четвъртата буква се използва за графични редактори (такива програми, които обработват изображенията). Ако буквата е малка, това указва на редактора, че парчето "безопасно" за копиране в нов файл. Ако е главна, парчето не трябва да се копира.
Четирите основни критични парчета са следните:
IHDR- винаги първо парче в PNG файла. То ще указва ширина, височина, битове на пиксел и цветово поле на картинката;PLTE- палитра с цветове за картинки с индексирани цветове;IDAT- съдържа парче от самата картинка - едно изображение може да бъде представено като едно или повече IDAT парчета;IEND- край на картинката.
Някои от спомагателните парчета са следните:
- bKGD - задава фонов цвят (често се пропуска и бива презаписан от програмата, с която се гледа изображението);
- gAMA - определя гама;
- hIST - съдържа хистограма на изображението;
- iCCP - ICC цветен профил;
- pHYs - размер на пиксела, по който може да се определя по-специфичен aspect ratio на картинката (писахме за подобно нещо при GIF);
- sRGB - указва, че се използва стандартен sRGB цветен профил;
- sTER - използва се за "стереоскопични" картинки;
- tEXt или zTXt - може да съдържа текст във формат "име=стойност";
- tIME - съдържа времето на последна промяна на картинката;
- tRNS - съдържа информация за прозрачността - при индексирани картинки съдържа информация за алфа канала.
Разбира се може да си представите, че всяко едно от тези парчета си има свое собствено "побитово" описание, което ще си спестим за тази статия. Важно е да се обърне малко внимание на компресирането на данните на самото изображение (IDAT парчетата) - то е двуфазово, т.е. се осъществява на две стъпки:
- Филтриране - използва се алторитъм, с който се прави така, че последващата компресия ще бъде значително по-ефективна. Взима се първото квадратче съставено от четири пиксела (горе-дясно на картинката) r се изчислява средната стойност на горните два и левия долен пиксел. Тази стойност се приема за т.нар. "предсказване" за стойността на четвъртия (долен десен). Тази стойност се вади от реалната стойност на четвъртия пиксел - в повечето случаи тя се получава близка до 0. Естествено съставена по този начин стойността може лесно да бъде възстановена. Този процес се повтаря за всички възможни квадратчета от по 4 пиксела (изображението после се възстановява от горен десен ъгъл надясно). Идеята на филтъра е да направи стойностите на повечето от пикселите близки или равни на 0. В идеалния вариант ще имаме картинка с много монотонни части, т.е. да много точни съвпадения с предказанията или в крайна сметка много нули;
- Компресиране - използва се т.нар. DEFLATE алгоритъм, който се базира на комбинация от "кодиране на Хъфман" и алгоритъм LZ77. DEFLATE стои в основата на компресирането със zip, gzip/zlib и др. компресиращи формати. Първо се изпълнява LZ77 - той е подобрен вариант на вече споменатия RLE алгоритъм. След това се извършва кодиране на Хъфман.
За прочитане на изображението се извършват обратните алгоритми - декомпресиране са INFLATE и обръщане на филтъра. Тази не чак толкова проста схема за компресиране обаче е много ефективна.
Joint Photographic Experts Group (JPEG)
JPEG e формат за запазване на изображения с настройваща се загуба на качество. В основата си използва усложнен вариант на кодирането на Хъфман. Няма да разглеждаме побитовото представяне на данните, а ще дадем само обща идея за алгоритъма.
Първата стъпка при компресирането в JPG формат е изображението да се превърне в YCbCr цветово поле. След това картинката се разделя на блокове от 8x8 пиксела (има допълнителни условия ако пикселите по хоризонтала или вертикала не се делят на 8, на тук ще ги пропуснем). Във всеки блок от яркостта се вади 127 с цел числата да се приближат усреднено към нула (в практиката рядко работим с прекалено тъмни или прекалено ярки снимки, затова ако стойностите са от 0 до 255, то средната стойност ще клони към 127). Забележете също така, че още на тази стъпка имаме извършена компресия ако YCbCr цветовото поле е с различен от 4:2:2 subsampling.
Следващата стъпка е извършване на дискретна косинусова трансформация. Това е преобразувание от линейната алгебра, при което матрицата на блока от 8x8 пиксела M се представя чрез линейна трансформация U в матрицата T = UMUt (всяка клетка от резултатната матрица може да сеполучи по точно определена формула, но няма да се спираме върху тези подробности). За простота ще кажем само, че по този начин в горния ляв ъгъл на блока се събират по-големите числа (по-важните за блока пиксели, които са по-осветени и с повече цветова наситеност), а тези с по-ниска осветеност и по-слаба наситеност запълват клетките към долния десен ъгъл на матрицата. Трябва да се отбележи, че на теория тази трансформация е обратима (т.е. тук няма загуба на информация), но на практика повечето от получените числа са ирационални, а както вече знаем компютъра не може да запазва безкрайно дълги числа. Поради тази причина тук все пак имаме минимална загуба на информация в следствие от записването на числата като числа с плаваща запетая.
Трансформацията продължава с процес на "квантуване" (quantization). Идеята му е, че човешкото око не различава подробности в местата с ниска осветеност. Например трудно се различават детайлите в сянката на даден човек в снимка. Затова тук просто си избираме "агресивност" на квантуването (в JPEG се определя с число от 0 до 100) и в зависимост от него всички стойности от десния ъгъл на матрицата се правят равни на 0. Останалите числа пък се закръгляват до цели. Тук очевидно имаме необратима загуба на информация.
Накрая, както вече казахме, се извършва кодиране на Хъфман, с което се извършва реалната компресия на данните. Естествено колкото повече 0-ли има в матрицата, толкова по-силна ще е компресията. Тук разбира се от чисто практическа гледна точка ще се търси баланс между ниво на компресия и загуба на качество. Понеже компресията се прави по блокове 8x8 пиксела, загубата на качество при JPEG се изразява в появяване на разпознаваем шум в различни части (блокове) на изображението. Самото възстановяване се прави чрез обратна косинусова трансформация, след която превръщане на изображението от YCbCr в RGB.
Tagged Image File Format (TIFF)
TIFF е формат с дълга история и няколко поредни ревизии (последната е версия 6.0). Идеята му е да може в един универсален формат да се запазват изображения с различна компресия. Подобно на други разгледани досега формати той се състои от заглавна част (header) и данни за изображението. Заглавната част няма да я разглеждаме подробно, но тя основно се състои от поредица от битове, в които се записва размера на изображението, подредбата на данните и използвания алгоритъм за компресиране.
Това, което прави удобен TIFF е, че той може да бъде разглеждан като "контейнер" за изображения. Дори има шеговита транскрипция като "Thousands of Incompatible File Formats" (хиляди несъвместими файлови формати) - реално използвани в практиката са малко над 20. Те могат да са както със загуба на качество, така и без загуба на качество. Стандартът дели TIFF на два формата - базов (baseline) и разширен (extensions).
Базовият формат указва няколко изисквания, основните от които са:
- Да се поддържа повече от едно изображение в един файл;
- Да може да се правят т.нар. "tiles" - повтаряне на едно малко изображение многократно по хоризонтала и/или вертикала в предварително дефинирано поле;
- Да може да се правят т.нар. "strips" - групи от редове с пиксели, като всяка група да може да се компресира отделно и независимо от останалите;
- Един от три вида компресии - без компресиране, CCITT Group 3 (вариант на кодиране на Хъфман и RLE) и PackBits (вариант на RLE);
- Цветови полета - сиво, с палитра или RGB32;
- Дефиниция за подредба на байтовете - Big Endian или Little Endian;
Разширения формат добавя възможности за допълнителни компресии - най-популярните сред тях са LZW, CCITT T.4 и CCITT T.6. Възможна е поддръжка и на DEFLATE и JPEG, но в практиката се използват рядко. Има още множество други варианти за компресия. Другото, което добавя е възможност за по-разнообразни цветови полета - CMYK, YCbCr и някои други.
Възможно е да има графични редактори, които поддържат само baseline TIFF - те не биха могли да отворят файлове от разширения формат. За съжаление обаче съществуват и много редактори, които поддържат само някои, но не всички разширения.
Обобщение
Като обобщение ще си позволим да дадем няколко практически съвета за употребата на изброените по-горе графични формати:
- При снимки, които трябва ще търпят бъдеща обработка и има изискване към много високо качество, използвайте формат TIFF с компресиране без загуба на качество (най-добре някоя от baseline компресиите). BMP също е удачен вариант, но се използва по-рядко за професионални цели;
- При снимки, които са за личен архив (няма да търпят обработка и няма да се разпечатват на големи постери и т.н.) си пазете изображенията в оригинален размер с компресия JPEG с ниско ниво на компресия (тоест слабо компресирани);
- При снимки, които ще се използват за публикуване в интернет, първо намалете размера на изображението (няма смисъл от огромни 24 мегапикселови изображения, защото компютърните екрани стандартно са 1920x1080 пиксела), както и използвайте JPEG с по-високо ниво на компресия. Целта е да се постигне задоволително качество, да пазим толкова пиксели, колкото максимално би била разпъната на екрана снимката, и най-вече минимален размер на изображението (в байтове), за да може да се зарежда максимално бързо в уеб браузъра. Много платформи като например Фейсбук автоматично преоразмеряват и прекомпресират изображенията, които качвате в тях;
- При графики с до 256 цвята използвайте GIF или PNG;
- При графики с над 256 цвята използдвайте PNG.
Надявам се да сме били полезни.
Добави коментар